Training a deep learning model to play The Witness

Spoiler Alert: I discuss major plot points of the game while describing my model.
In the game The Witness, players solve puzzles by tracing patterns that begin with circles, and continue in continuous line to and endpoint point. At first these patterns appear only on panels, but players eventually realize that the entire island is filled with these patterns, and the real goal is to recognize these patterns in the surrounding environment. And after finishing, many players, myself included, began seeing these patterns in the real world as well.

I trained a deep learning model to identify and label those puzzle patterns in The Witness screenshots. I'm an experienced web engineer but new to machine learning, and I'm particularly interested in machine learning for artistic and creative purposes. This seemed like a simple enough entry point where I could learn a bit about deep learning techniques and generate some interesting results along the way.
I was able to achieve some promising results! In this post, I'll walk you through the process I took to get there. I've also published a reproducible repo with the project, and would be thrilled if other Witness fans would want to collaborate to improve the project.
Gathering Data and Refining the Task
First, I went through the game and took several screenshots of each environmental puzzle: about 300 in total. Thanks to IGN for this comprehensive guide to the locations of all the puzzles, and SaveGameWorld for a save file so I didn't have to actually gain access to all the locations again! I made sure to capture screenshots from different angles, plenty of positive examples with the puzzle fully visible, and negative examples where parts are obscured or interrupted.

I created the training labels for each of these screenshots manually, in Photoshop. To make things faster, I created an Action to automate the repetitive steps. I used the "Select & Mask" tool to manually select the puzzle area, if one was present, and then triggered an Action to convert the selection mask into a black and white image, and save it as a PNG in the "labels" folder.

One of the most interesting aspects of machine learning in my experience has been how the process of developing the code can result in several iterations of reframing and redefining the problem at hand. My initial framing of the problem: "Identify and label environmental puzzle patterns matching the rules of The Witness," turned out to be imprecise. Many situations arose upon building the training set that challenged me to refine the definition of what portions of the image should be labeled as a puzzle.
For the circular shape that begins every puzzle pattern:
- Is a circle that is obscured by an object in the foreground acceptable?
- Is a circle that is not completely visible within the viewport acceptable?
- What degree of unevenness or deviation in the boundary of the circle is acceptable?
- What degree of angle of viewing for the circle is acceptable?
And for the line that comprises the rest of the pattern:
- Is a line that extends out of the viewport without concluding acceptable?
- What degree of widening or narrowing of the line is acceptable?
- What degree of color transition within the line or circle is acceptable?
- If a transparent material (laser, or shadow) is superimposed on the line, should it be counted as an interruption of the line? Should it be labeled as part of the line?
Model Architecture
At the heart, this task is commonly called "semantic segmentation". The model must label which pixels of an image belong to a certain type of object. I chose a model architecture commonly used for this kind of task, the U-Net, which was initially developed for segmentation of medical images.
A U-Net has a contracting path, or encoder (the left side of this image), which develops feature detection capability through several layered convolutional layers, and an expanding path, or decoder (on the right), which creates a semantic map of the entire input image by merging the feature information from the bottom of the U with locational information from the contracting layers.
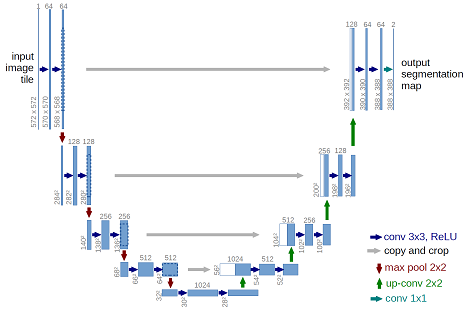
I used this U-Net example code to get started.
Running the Code
You can run the code yourself, no experience necessary!
git clone git@github.com:wandb/witness.git
pip install -r requirements.txt
wandb init # Init on W&B to save your run results
./process.py # Split data from /data/all into a training and validation sets
./train.py # Train your model, and save the best one
./predict.py # Output the prediction for all examples in the validation set
I used a p3.2xlarge instance on Amazon EC2 to run the training. These instances all have GPUs for much faster training. I used the Ubuntu Deep Learning AMI, which pre-installs all the commonly needed python libraries and binaries.
Initial Results
Even the very first run yielded informative and promising results. I've written up a W&B report exploring my results.
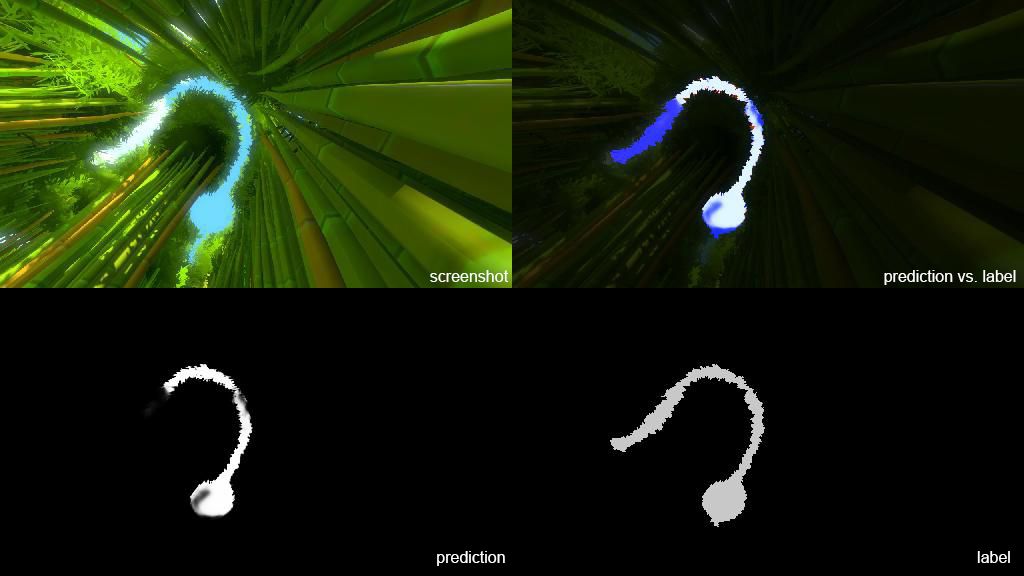
After saving the best performing model, I used the predict.py script to identify examples where the training data was incorrectly labeled or ambiguous, or where the game itself made for a particularly challenging example. In each of these examples, the top left is the screenshot, bottom left is prediction, bottom right is my hand-created label, and the top right is a composite of the label and prediction. In the composite, white indicates true positive, red indicates false positive, and blue indicates false negative.








Refining Training Data and Retraining the Model
Based on the confounding cases above, I refined the training data to remove mask errors and clarify the rules used to generate training data. Here's a W&B report showing the improvement from Run 1 to Run 2: accuracy clearly increases!
I ran into a weird problem where many of my runs were getting stuck without learning anything, seemingly non-deterministically. Thanks to some help from my colleagues, we identified that sometimes, based on the random seed, the training was unable to explore outside of the local minimum of an empty prediction: since most positive labels would be incorrect and increase loss. Using the weighted cross entropy loss function, weighting the algorithm to prefer positive predictions to negative ones, resolved the issue.
I also experimented with the number of "tiers" in the U-Net, based on the intuition that the 5-tier example might be too large for the problem. You can see a report comparing these hyperparameters here. One learning was that more compact models learned more slowly on the training set, but performed better on the validation set, implying that they are worse at memorizing but are generalizing better.
Introspecting the model
One of the most interesting parts of machine learning for me is investigating the inner structure of a trained model to discover meaningful emergent forms and behaviors. I wrote a script, visualize.py, that breaks down a simple 3-tier version of the U-Net and visualizes the intermediate layers of the trained neural net.
In most deep convolutional neural nets, the earlier layers tend to learn to encode fine patterns, whereas the later layers, closer to the desired output, tend to encode more semantic meaning. You can see this pattern in this network as well.
Here's a visualization of the activation of each cell in the 2nd layer. This black and white image is the raw activation of each cell on a single example image. White means that cell is activated by that part in the image.

It's easier to parse when you colorize the activated areas by the hue of the source example. You can see how some cells are acting as rough edge detectors, and others activate on flat regions like sky, and others activate on fine patterns.

Deep in the neural net (layer 12 at the bottom of the U) the cells become more difficult to parse, as they're capturing very small snippets of regional information.

And as you get towards the end, you can see that the network has identified many meaningful portions of this image. Many cells have identified the puzzle pattern. Others call out sky, fence, or flowery regions.

Even more interesting is when you visualize the output of a single cell in the network across all examples in the dataset. Here's a cell in layer 12 that's learned to identify sky regions, but also identifies the puzzle in a few cases.

Here's one cell in layer 19, the second-to-last layer, that has clearly learned to identify the puzzle pattern in most of the example images.

And another cell in the same layer that seems to be identifying the edge region around the puzzle in most examples.

Next Steps
There are many possible avenues for improving the performance of this model, falling into two main categories: improving the training data and improving the model architecture.
To increase and improve the training data, we have a number of options.
- More data. We could go through the game and take more screenshots and manually label them using the existing process. This is time-consuming but technically simple.
- Field-of-view for data augmentation. The camera field of view for the game renderer is configurable in the settings page. Gathering training data at many different fields of view could help make the model more robust.
- Refine data augmentation. The current model uses some default rules for data augmentation. These could be improved -- for example, if a crop function cuts off a portion of a puzzle circle, it may preserve a puzzle label that has become incorrect.
- Synthetic data. In a perfect world, we could have access to a custom build of the game that could output the internal representation of puzzle regions along with a screenshot. If we had that, we could generate tens of thousands of renderings with perfect labels through automation.
- Better training/validation split. The training and validation sets are randomly split from the collection of screenshots, which means that there is no guarantee that each item in the validation set is a novel puzzle for the model. A better test that the model is truly generalizing would be to ensure some puzzles only appear in the validation set.
There are also a number of ways to improve the algorithm and model:
- Transfer learning. One could use a pre-trained model, like ResNet, for the contracting layers, which would allow the model to utilize all the learned features from a far larger training dataset.
- Alternate architectures. One could imagine an alternative where one model takes a screenshot as an input and generates a set of possible puzzle candidates as black and white masks. Then a second model filters the candidates into a final set of acceptable puzzles. This approach could make expanding the training data much easier, as it's much simpler to generate synthetic 1-bit masks than it would be to generate synthetic RGB game screenshots.
Expanding to Real World Imagery
The original intention of this project was to find The Witness patterns in the real world, like in the WitnessIRL reddit thread. I ended up reducing the scope of the project, as identifying the patterns in screenshots was challenging enough, and the ~100 images in that thread is not a sufficient training set to make meaningful progress. However, with a model trained on game screenshots, I believe transfer learning could be used to get a head start on a model that detects the patterns in real-world photos. The dream would then be to run the model on a large image dataset: for instance the Flickr Creative Commons 100M photo dataset.